This post was originally published on this site
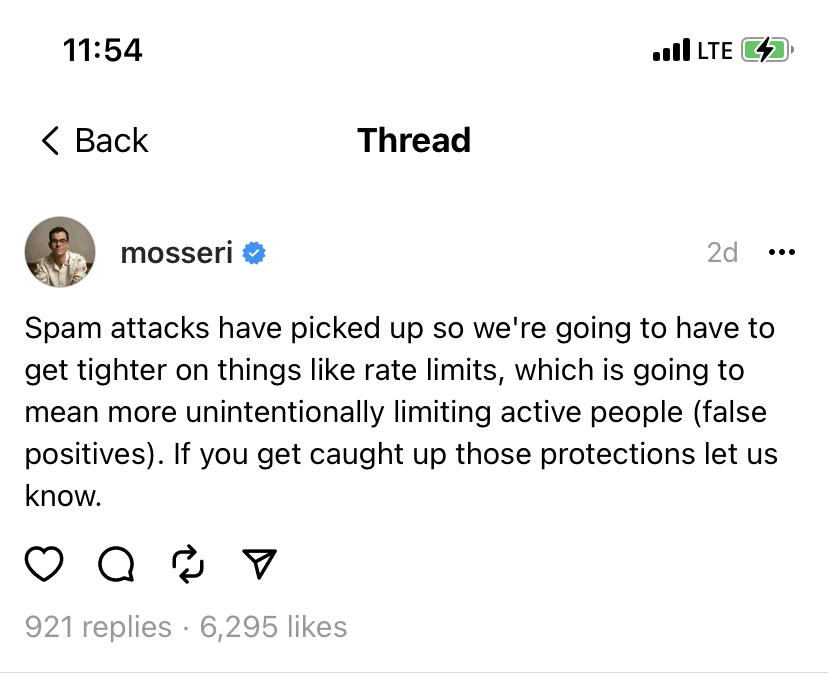
https://content.fortune.com/wp-content/uploads/2023/07/GettyImages-1258928014-1-e1689785566695.jpg?w=2048“Spam attacks have picked up so we’re going to have to get tighter on things like rate limits, which is going to mean unintentionally limiting active people (false positives),” Mosseri writes. “If you get caught up those [sic] protections let us know.”
Meta’s measures come just over a week since its launch saw 43 million people sign up to the platform, although only about 24 million are now daily active users. Meta CEO Mark Zuckerberg seemed unbothered by the drop-off, however, saying the numbers were “ahead of what we expected.”
Several weeks ago, Twitter adopted a similar policy as Threads of limiting use, which had prompted intense criticism by users who ended up being blocked from seeing as many posts on the service as they wanted to. At the time, Twitter owner Elon Musk said in a tweet that limiting the number of posts users could see on a daily basis were “temporary” measures to address mass data scraping on the website by third parties.
Data scraping is when third parties extract large amounts of information from websites—often to create databases that are then used to generate sales leads, collect insights about consumers or to spam users. When done at large scale it can strain the target’s servers and slow its website. Musk said this was the case on Twitter.
When Twitter instituted its rate limits, many experts called it an unorthodox solution for a social media company that makes money when users see more ads. Limiting the number of posts users can see risks reducing the amount of time they spend on the platform and therefore less ad revenue for the company.
When Threads announced it would follow Twitter’s lead, Musk crowed that he had been vindicated, calling Mosseri and Meta “copy cats” on Twitter.
Based on Mosseri’s comments, it appears Meta is trying to only place limits on suspected bots and not on all Threads users. Any real people caught up in the effort—or false positives, as he put it—would be inadvertent.
More recently, data scraping has been the subject of discussion because A.I. companies regularly do it to gather information that they then use to train their large language models. Critics say doing so violates intellectual property and privacy laws. Major A.I. developers like Alphabet and OpenAI were recently hit with class action lawsuits over data scraping.